


Facebook and its sister properties Instagram and WhatsApp are suffering from ongoing, global outages. We don’t yet know why this happened, but the how is clear: Earlier this morning, something inside Facebook caused the company to revoke key digital records that tell computers and other Internet-enabled devices how to find these destinations online.
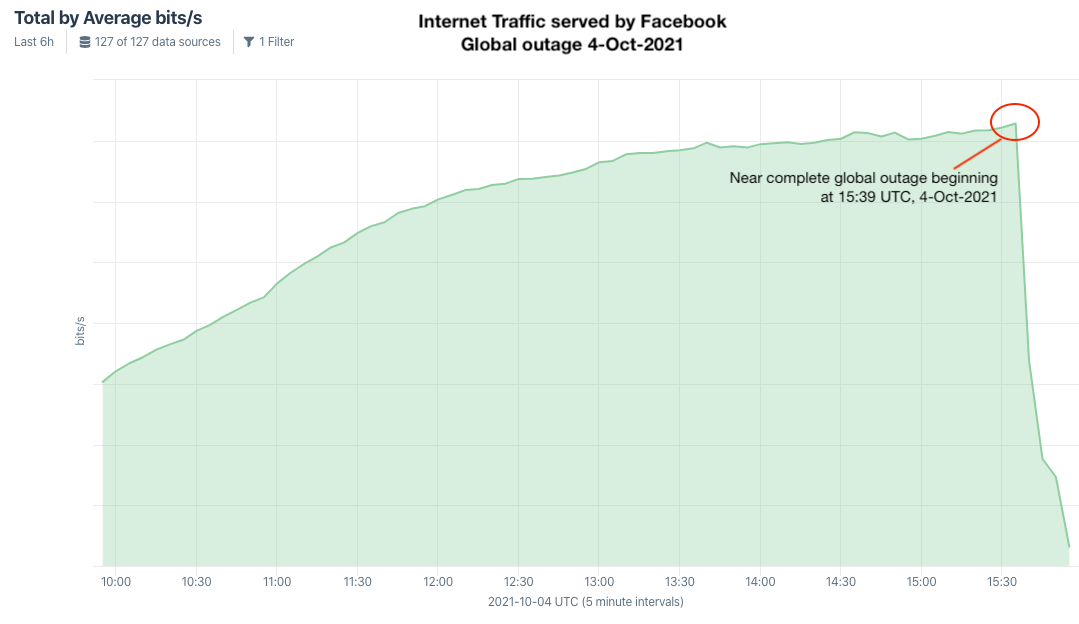
Kentik’s view of the Facebook, Instagram and WhatsApp outage.
Doug Madory is director of internet analysis at Kentik, a San Francisco-based network monitoring company. Madory said at approximately 11:39 a.m. ET today (15:39 UTC), someone at Facebook caused an update to be made to the company’s Border Gateway Protocol (BGP) records. BGP is a mechanism by which Internet service providers of the world share information about which providers are responsible for routing Internet traffic to which specific groups of Internet addresses.
In simpler terms, sometime this morning Facebook took away the map telling the world’s computers how to find its various online properties. As a result, when one types Facebook.com into a web browser, the browser has no idea where to find Facebook.com, and so returns an error page.
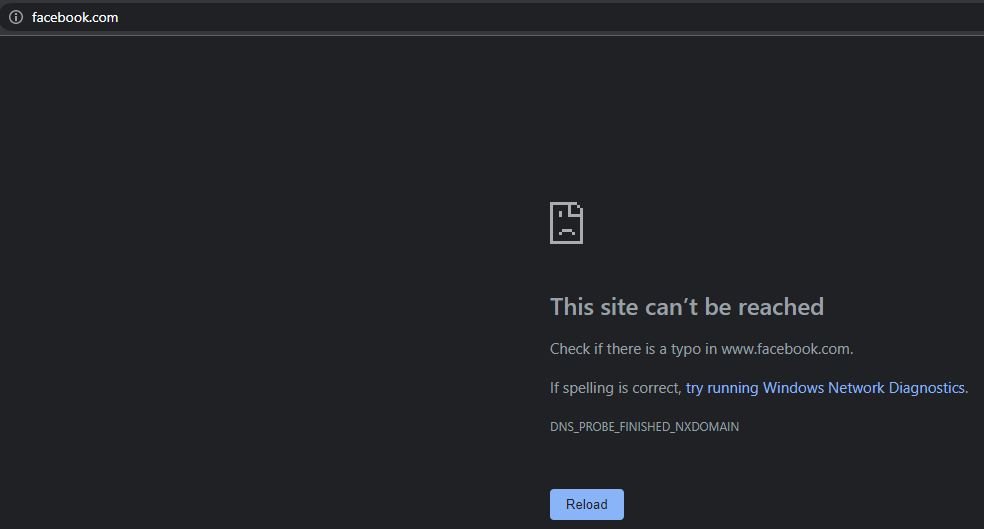
In addition to stranding billions of users, the Facebook outage also has stranded its employees from communicating with one another using their internal Facebook tools. That’s because Facebook’s email and tools are all managed in house and via the same domains that are now stranded.
“Not only are Facebook’s services and apps down for the public, its internal tools and communications platforms, including Workplace, are out as well,” New York Times tech reporter Ryan Mac tweeted. “No one can do any work. Several people I’ve talked to said this is the equivalent of a ‘snow day’ at the company.”
The outages come just hours after CBS’s 60 Minutes aired a much-anticipated interview with Frances Haugen, the Facebook whistleblower who recently leaked a number of internal Facebook investigations showing the company knew its products were causing mass harm, and that it prioritized profits over taking bolder steps to curtail abuse on its platform — including disinformation and hate speech.
We don’t know how or why the outages persist at Facebook and its other properties, but the changes had to have come from inside the company, as Facebook manages those records internally. Whether the changes were made maliciously or by accident is anyone’s guess at this point.
Madory said it could be that someone at Facebook just screwed up.
“In the past year or so, we’ve seen a lot of these big outages where they had some sort of update to their global network configuration that went awry,” Madory said. “We obviously can’t rule out someone hacking them, but they also could have done this to themselves.”
Update, 4:37 p.m. ET: Sheera Frenkel with The New York Times tweeted that Facebook employees told her they were having trouble accessing Facebook buildings because their employee badges no longer worked. That could be one reason this outage has persisted so long: Facebook engineers may be having trouble physically accessing the computer servers needed to upload new BGP records to the global Internet.
Update, 6:16 p.m. ET: A trusted source who spoke with a person on the recovery effort at Facebook was told the outage was caused by a routine BGP update gone wrong. The source explained that the errant update blocked Facebook employees — the majority of whom are working remotely — from reverting the changes. Meanwhile, those with physical access to Facebook’s buildings couldn’t access Facebook’s internal tools because those were all tied to the company’s stranded domains.
Update, 7:46 p.m. ET: Facebook says its domains are slowly coming back online for most users. In a tweet, the company thanked users for their patience, but it still hasn’t offered any explanation for the outage.
Update, 8:05 p.m. ET: This fascinating thread on Hacker News delves into some of the not-so-obvious side effects of today’s outages: Many organizations saw network disruptions and slowness thanks to billions of devices constantly asking for the current coordinates of Facebook.com, Instagram.com and WhatsApp.com. Bill Woodcock, executive director of the Packet Clearing House, said his organization saw a 40 percent increase globally in wayward DNS traffic throughout the outage.
Update, 8:32 p.m. ET: Cloudflare has published a detailed and somewhat technical writeup on the BGP changes that caused today’s outage. Still no word from Facebook on what happened.
Update, 11:32 p.m. ET: Facebook published a blog post saying the outage was the result of a faulty configuration change:
“Our engineering teams have learned that configuration changes on the backbone routers that coordinate network traffic between our data centers caused issues that interrupted this communication,” Facebook’s Santosh Janardhan wrote. “This disruption to network traffic had a cascading effect on the way our data centers communicate, bringing our services to a halt.”
“We want to make clear at this time we believe the root cause of this outage was a faulty configuration change,” Janardhan continued. “We also have no evidence that user data was compromised as a result of this downtime.”
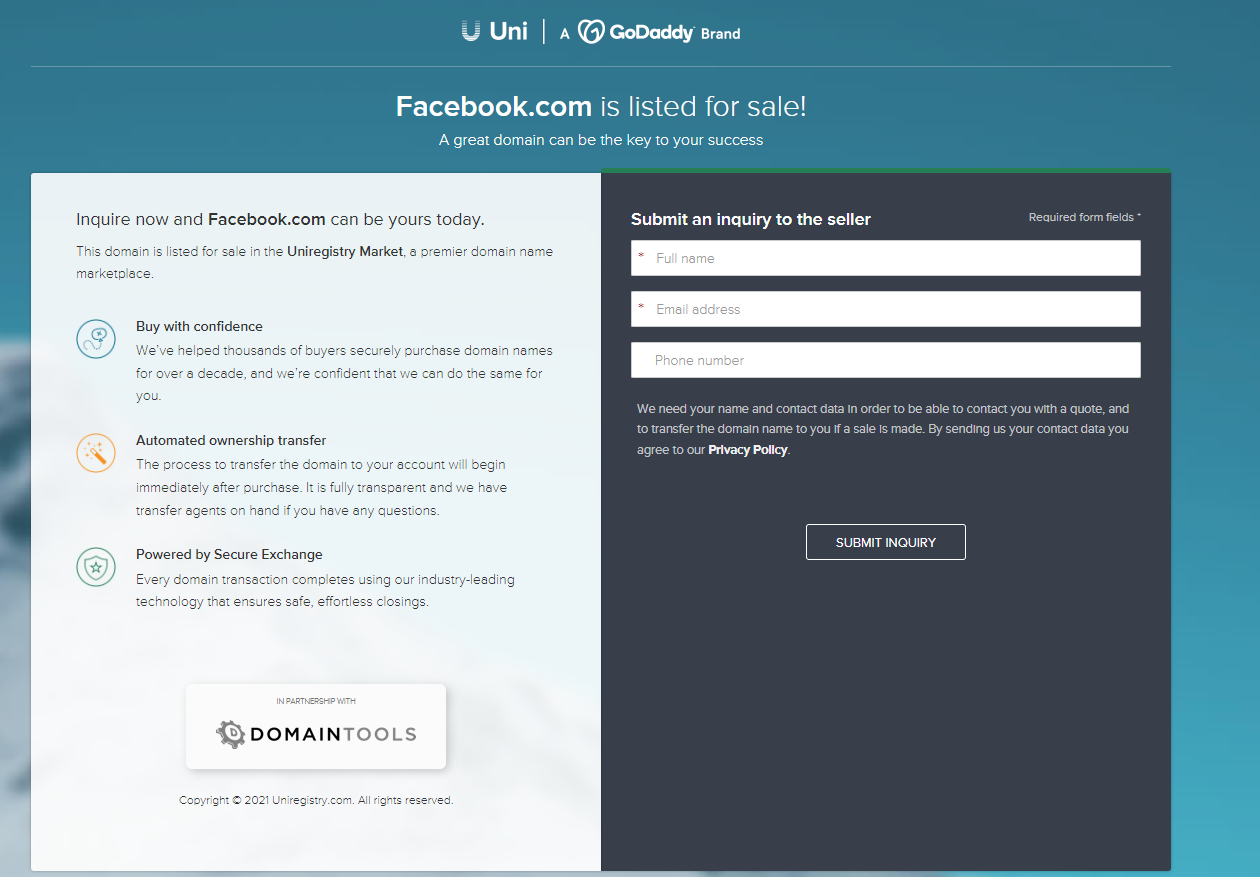
Several different domain registration companies today listed the domain Facebook.com as up for sale. This happened thanks to automated systems that look for registered domains which appear to be expired, abandoned or recently vacated. There was never any reason to believe Facebook.com would actually be sold as a result, but it’s fun to consider how many billions of dollars it could fetch on the open market.
This is a developing story and will likely be updated throughout the day.

Cisco offers a service called Crosswork Network Insights that monitors changes in BGP routing advertisements. Had Facebook been using this service, they likely could have identified and mitigated the problem a lot faster. Give our white paper a read to understand what likely happened at Facebook.
https://www.cisco.com/c/en/us/products/cloud-systems-management/crosswork-network-automation/the-risks-of-traffic-hijacking.html#~how-bgp-works
The map metaphor is very good for BGP, but your pictured error is from DNS which is really the phone book.
Basically the map to places on Facebook’s network was withdrawn, and the DNS phone books then stopped listing addresses (this isn’t a default DNS implementation, it’s a specific “quirk” of Facebook’s implementation). Thus browsers didn’t know what address to ask to go to, which meant that routers didn’t have to try and fail to figure out where to send them (as there were no longer maps explaining where they should go).
I think that technically someone with a cached DNS entry could have received a connection timed out error.
Something like:
> Try:
> Checking the connection
> ERR_CONNECTION_TIMED_OUT
Practically, Facebook’s DNS records are configured with a 5 minute duration (imagine looking something up in a phone book and being told you can only reach the entity at the listed number/address for the next 5 minutes), so very quickly the BGP (no map) problem was replaced by an “empty phone book” problem.
Funny comments, some joking but some serious. The same conspiracy theorists who hate Facebook for labeling/flagging their posts on Facebook, are conflicted about the Whistleblower’s revelations that after Facebook stopped flagging them their algorithm promoted their conspiracy theories.
–
Now, there are a bunch of conspiracy theorists here saying that a massive outage that cost Facebook so much more money and did so much more lasting reputational damage, was a cover up to distract from the whistleblower who only confirmed what was already suspected about the FB algorithm.
Even a 6 hour outage costs Facebook millions in ad revenue, billions in stock damage, and far more reputational damage as people are more hesitant to rely on Facebook, WhatsApp, Instagram now that it is apparent that a major outage can occur.
The conspiracy theory of a cover up makes no sense, to burn down an entire building just to distract from a dumpster fire.
–
https://engineering.fb.com/2021/10/05/networking-traffic/outage-details/
Yes, this is Facebook’s official account, but it really doesn’t paint them in good light. They acknowledge their own massive failure and they come across as incompetent.
–
Hanlon’s Razor and Occam’s razor both apply here. Fewest assumptions and assuming stupidity over intentional malice.
“Never attribute to malice that which is adequately explained by stupidity.”
–
The explanation of Facebook’s stupidity and incompetence covers this entire debacle. No need to foster and spread even more conspiracy theories.
The same conspiracy theorists who hate Facebook for labeling/flagging their posts on Facebook, are conflicted about the Whistleblower’s revelations that after Facebook stopped flagging them their algorithm promoted their conspiracy theories.
–
Now, there are a bunch of conspiracy theorists here saying that a massive outage that cost Facebook so much more money and did so much more lasting reputational damage, was a cover up to distract from the whistleblower who only confirmed what was already suspected about the FB algorithm.
Even a 6 hour outage costs Facebook millions in ad revenue, billions in stock damage, and far more reputational damage as people are more hesitant to rely on Facebook, WhatsApp, Instagram now that it is apparent that a major outage can occur.
The conspiracy theory of a cover up makes no sense, to burn down an entire building just to distract from a dumpster fire.
–
https://engineering.fb.com/2021/10/05/networking-traffic/outage-details/
Yes, this is Facebook’s official account, but it really doesn’t paint them in good light. They acknowledge their own massive failure and they come across as incompetent.
–
Hanlon’s Razor and Occam’s razor both apply here. Fewest assumptions and assuming stupidity over intentional malice.
“Never attribute to malice that which is adequately explained by stupidity.”
–
The explanation of Facebook’s stupidity and incompetence covers this entire debacle. No need to foster and spread even more conspiracy theories.
SINCE LAST THREE DAYS i AM UNABLE TO OPEN MY FACE PAGE DUE TO THIS MESSAGE
ERR_CONNECTION_TIMED_OUT
I’d like to know the name, function, and provenance of the buggy audit tool that failed to stop the faulty command that created the outage rather than query the backbone about its capacity like it was supposed to do. No matter what you say about Facebook’s approach from there on out, it was the fault by the buggy audit tool that started it all on that particular day, according to Facebook.