


A ransomware outbreak that hit QuickBooks cloud hosting firm iNSYNQ in mid-July appears to have started with an email phishing attack that snared an employee working in sales for the company, KrebsOnSecurity has learned. It also looks like the intruders spent roughly ten days rooting around iNSYNQ’s internal network to properly stage things before unleashing the ransomware. iNSYNQ ultimately declined to pay the ransom demand, and it is still working to completely restore customer access to files.

Some of this detail came in a virtual “town hall” meeting held August 8, in which iNSYNQ chief executive Elliot Luchansky briefed customers on how it all went down, and what the company is doing to prevent such outages in the future.
A great many iNSYNQ’s customers are accountants, and when the company took its network offline on July 16 in response to the ransomware outbreak, some of those customers took to social media to complain that iNSYNQ was stonewalling them.
“We could definitely have been better prepared, and it’s totally unacceptable,” Luchansky told customers. “I take full responsibility for this. People waiting ridiculous amounts of time for a response is unacceptable.”
By way of explaining iNSYNQ’s initial reluctance to share information about the particulars of the attack early on, Luchansky told customers the company had to assume the intruders were watching and listening to everything iNSYNQ was doing to recover operations and data in the wake of the ransomware outbreak.
“That was done strategically for a good reason,” he said. “There were human beings involved with [carrying out] this attack in real time, and we had to assume they were monitoring everything we could say. And that posed risks based on what we did say publicly while the ransom negotiations were going on. It could have been used in a way that would have exposed customers even more. That put us in a really tough bind, because transparency is something we take very seriously. But we decided it was in our customers’ best interests to not do that.”

A paid ad that comes up prominently when one searches for “insynq” in Google.
Luchansky did not say how much the intruders were demanding, but he mentioned two key factors that informed the company’s decision not to pay up.
“It was a very substantial amount, but we had the money wired and were ready to pay it in cryptocurrency in the case that it made sense to do so,” he told customers. “But we also understood [that paying] would put a target on our heads in the future, and even if we actually received the decryption key, that wasn’t really the main issue here. Because of the quick reaction we had, we were able to contain the encryption part” to roughly 50 percent of customer systems, he said.
Luchansky said the intruders seeded its internal network with MegaCortex, a potent new ransomware strain first spotted just a couple of months ago that is being used in targeted attacks on enterprises. He said the attack appears to have been carefully planned out in advance and executed “with human intervention all the way through.”
“They decided they were coming after us,” he said. “It’s one thing to prepare for these sorts of events but it’s an entirely different experience to deal with first hand.”
According to an analysis of MegaCortex published this week by Accenture iDefense, the crooks behind this ransomware strain are targeting businesses — not home users — and demanding ransom payments in the range of two to 600 bitcoins, which is roughly $20,000 to $5.8 million.
“We are working for profit,” reads the ransom note left behind by the latest version of MegaCortex. “The core of this criminal business is to give back your valuable data in the original form (for ransom of course).”
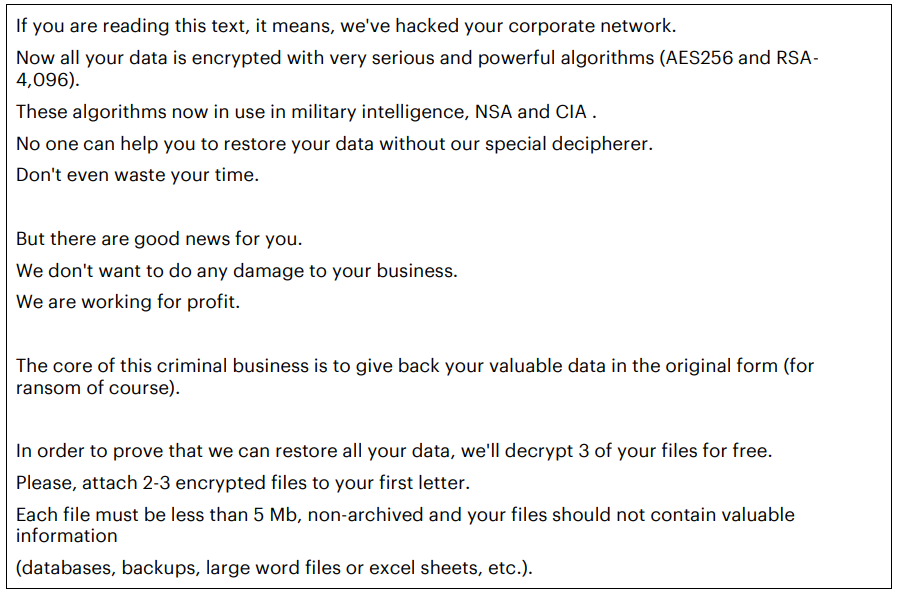
A portion of the ransom note left behind by the latest version of MegaCortex. Image: Accenture iDefense.
Luchansky did not mention in the town hall meeting exactly when the initial phishing attack was thought to have occurred, noting that iNSYNQ is still working with California-based CrowdStrike to gain a more complete picture of the attack.
But Alex Holden, founder of Milwaukee-based cyber intelligence firm Hold Security, showed KrebsOnSecurity information obtained from monitoring dark web communications which suggested the problem started on July 6, after an employee in iNSYNQ’s sales division fell for a targeted phishing email.
“This shows that even after the initial infection, if companies act promptly they can still detect and stop the ransomware,” Holden said. “For these infections hackers take sometimes days, weeks, or even months to encrypt your data.”
iNSYNQ did not respond to requests for comment on Hold Security’s findings.
Asked whether the company had backups of customer data and — if so — why iNSYNQ decided not to restore from those, Luchansky said there were backups but that some of those were also infected.
“The backup system is backing up the primary system, and that by definition entails some level of integration,” Luchansky explained. “The way our system was architected, the malware had spread into the backups as well, at least a little bit. So [by] just turning the backups back on, there was a good chance the the virus would then start to spread through the backup system more. So we had to treat the backups similarly to how we were treating the primary systems.”
Luchansky said their backup system has since been overhauled, and that if a similar attack happened in the future it would take days instead of weeks to recover. However, he declined to get into specifics about exactly what had changed, which is too bad because in every ransomware attack story I’ve written this seems to be the detail most readers are interested in and arguing about.
The CEO added that iNSYNQ also will be partnering with a company that helps firms detect and block targeted phishing attacks, and that it envisioned being able to offer this to its customers at a discounted rate. It wasn’t clear from Luchansky’s responses to questions whether the cloud hosting firm was also considering any kind of employee anti-phishing education and/or testing service.
Luchansky said iNSYNQ was able to restore access to more than 90 percent of customer files by Aug. 2 — roughly two weeks after the ransomware outbreak — and that the company would be offering customers a two month credit as a result of the outage.

The statement that the backups are infected suggests that iNSYNQ is not following the 3-2-1 rule. Data does not take up that much space and they should have multiple offline backup archives. Alternatively, if they are worried about restoring the backups, they could use a Unix or Linux system to access the data files and restore those on a clean system image.
Anti-phishing training is useful, but it will never be foolproof.
Even as a lowly sole-proprietor consultant I understand how to have multiple levels of data backup and isolation. I would never jeopardize my customers (my business) by not being as careful as possible.
But I do have some customers that don’t take this as seriously. And it is their bottom lines and livelihoods that are at risk.
Brian,
There are a few things that are of great concern here:
1: Why was iNSYNQ’s cloud services systems on the same network as their production day to day business?!?
2: In the post-event statement on iNSYNQ’s site they claimed that they “meticulously cleaned and verified your data” but can they be totally sure that there is no backdoor?
Trust is lost here.
And, what’s really sad here, is that folks are becoming tolerant of such things. 🙁
Another good article !
Hi Brian,
Any word from iNSYNQ on whether or not they have insurance that will cover some of the costs of the breach?
Thanks!
Here’s some translation of what that CEO guy was saying: “all their backups were simply made on a network share without any versioning support. So all of it was encrypted by the malware.”
Why wouldn’t they just say that instead of giving us all that highfalutin nonsense?
So now he is probably signing up for an expensive cloud-based backup service, when all it needed is just the properly configured network (preferably segmented) with proper permissions/ACLs set up and a backup that supports versioning.
When will companies learn?
For everyone who claims that proper backups are the foolproof way to fight ransomware, consider what happens as in this case where the attackers have 10 days to work in the system. By encrypting a random sample of files over time, the backup now contains a mix of good and bad backups. “No problem – just pick an earlier time to restore”? Now updated data will be lost. The restore procedure becomes a manual operation where the restore of for each file requires picking the most recent unencrypted copy.
So backups are just one step in countering ransomware. The rest of the network must be built for early intrusion detection as well – which many companies don’t have the luxury to do.
+1
Just how does this affect individual businesses and their customers? Ex.:
Insurance payment for repair routed to CustomerY’s bank account. BusinessA ‘construction’ sends Repair Invoice via email to CustomerY with a link to pay. CustomerY wants to pay BusinessA with debit card via the BusinessA email link which uses iSYNCQ payment method based in the cloud.
There’s news that ransomware hits payment method used by BusinessA’s — iSYNCQ.
HALT….
So what can CustomerY do to insure that the payment credentials used in the payment method are not somehow compromised or gobbled up and now can be used by the gobbler to gobble up CustomerY’s funds?
First off, unless a hosting provider does not allow email into their environment, this is always a risk of happening. We do not allow email in our environment, 99% of the risks are eliminated this way. Until iNSYNQ follows our lead, there will always be risks of this happening again.
Further more, when he said that it would have made no difference if the backups were located at a different location (after he admitted the backups were also infected). That means that :
1- Their backups are on site. and connected to the same LAN .. (which is kind of dumb)
2- The malware had been on their system for more than 24 hours , which fell in their backup window, which backed up encrypted data.
Tired of excuses and outages? Give us a call and experience serious security. gotomyerp.com
As the first paragraph says, the intruders were in the system for some ten days before unleashing the encrypting malware; I’m certain that over a week a determined attacker can also figure out some way to silently corrupt the backups so that at the time of encryption your latest good backups are at least multiple days old.
+1
Mike,
Proper segmentation and a Privileged Access Workstation (Microsoft’s proposal) structure to keep things completely separate are one of the two keys. The other is “Train the Human”.
No system on the corporate network should be able to route into the tenant environments or the compute, storage, and network fabric clusters. None. Nadda. Zippo. Zilch. Ever.
Systems used to manage them are on their own. Period.
E-mail is only one attack vector. Someone using a PAW could be hit by a web drive-by while browsing then we’re right back in the iNSYNQ, CCH/Wolters Kluwer/Maersk/PCM/ETC. boat.
Processes can be put in place to make this work. It’s a bit on the inconvenient side for _us_, but what’s inconvenience when we have hundreds, if not thousands, of customers now in an untrusted infrastructure state as in iNSYNQ?
@ Mike Murphy
The very first line of his post should be a lesson to all of us – so very obvious that we do not see this risk and therein lies the solution.
Thank you Mike
We’re all so grateful that you decided to gratuitously pimp your business here.
I mean, if your reading comprehension is any indication of your tech savvy, I think I’ll stick with Geek Squad.
After all this time, publicity, and employee training, anyone who falls for a corporate phishing attack should be fired for just being too stupid to work there.
never seen a top flight spearphishing attack have you?
I’ve worked in a highly targeted environment and have seen attacks where only my ability to decode RFC 822 format headers and to correlate the results with cyber threat intel feeds allowed recognition of malicious messages.
Overconfidence is deadly.
Exactly so. Professional phishing has got very sophisticated. Humans can pick up on the obvious ones, but increasingly it is OUR responsibility to have automated scanning that can detect suspicious emails, and mitigate the consequences. But hey, let’s blame the users, and sack them, for falling for an email that even takes me a couple of looks before I can see it. While it’s true that humans are the front line in this, and do need training, a layered security approach means … well, that there’s a couple more layers.
Agreed that more details would allow everyone to learn from the incident. Too bad we can’t take advantage of the lessons learned. Thanks for the follow up story.
I have what is perhaps a naive question. But why would someone be able to get to the internal network through Sales’ computers? One would think the sales/accounting/etc computers would be on a totally different/firewalled network from the IT operation and especially the customer’s databases.
I don’t mean this to sound to condescending, but if all you have to do is snare a salesperson to infect the entire network, then the phising should be fairly easy. Sales employees typically have many incentives to bypass security.
When one party has more knowledge than the other, and they are out to get you… Guess what?
if systems are virtual but on same hardware then admin must keep to be updated with patch, they use virus program to install bad software. like gun to childs head demanding money. must patch all computers even virtual must space network places. they turn off power in winter for funny but in ukraine the poor die. sorry poor english.
ms windows. it’s usually the problem.
Ahem, good article Brian. Interesting comments. Yes, everyone knows there is a problem out there. But, how do you stop it? I’m glad to see they only hire the best and brightest for their companies, know all the foreseeable problems, even those no one has heard of yet, and fire the people on a daily basis because people are the problem. They do not invest in training even in the latest problems and use the most secure practices. Snark, yup. Everyone does, right? So there should be no problems. Right! Wrong. Little businesses cannot hire someone from the ivy covered institutions, it’s not good business. Usually, their ego is in the way. And they need profits to keep their business open. So they hire jo/ Joe blow, the mid range tech who sets up their system. Who doesn’t know all the future systems or hope they ” should” set up their system. It’s made for today’s standard, not tommorows. The company has been in operation for several years, they update their system and somehow left one door open. Not impossible. They just didn’t see that as a problem then. But now?like they said, they now have to improve. More power to them.
Rule Number One: ALWAYS Backup Up LOCALLY.
Rule Number Two: Any Questions? See Rule Number ONE
True, however you have to have off site backup capability for physical threats such as fire, flood, weather, etc. Without that capability you’re risking data loss, IMHO.
I follow triple redundancy methods. Local backups, cloud backups (actually hybrid backups that do both local and cloud, with the local backup appliance in a seperate part of the building behind building firewalls), and take home backups for the really critical data such as password spreadsheets, volume license keys, etc., encrypted of course.
how many terabytes do you routinely back up on prem? what’s your network infrastructure look like to move that much data in the time window required, without impacting other production ops? how is your multi-site coop plan orchestrated to integrate that on-prem backup strategy?
Most things look easy, except at scale…
The need for continuous security awareness training for staff can not be over emphasized, it remains the only great remediation for social engineering.
if attacks like this?
usa seems to be main cyber criminals target now…
and average joe has no clue..about cyber security…
ransom attacks everywhere,
best is just load up your btc wallets to pay up ur ransome bills.
no brain=big wallet ..lol
wtfamily camp.. financial pain is the ultimate teacher when profits and convenience are placed higher then basic data backup policy
it doesnt matter how trained in social engineering employees are.. people and machines make mistakes..but not backing up critical data offline… lol bro…
two words.. “faking retarded”.. pardon my french
You’re all [the storage] I ever wanted
You’re all [the disk space] I ever needed, yeah
So tell me what to do now
‘Cause I want you [to] back [up your data]
Multiple offline backups were suppose to have been put in place.
We use Carbonite E2. We’re provided a backup appliance on site that does daily incremental backups and those get replicated to the cloud. The backup appliance is basically invisible except to the backup client. Backups are encrypted AES256 to the cloud for HIPPA compliance.
Has anybody used this product? If so what are your thoughts on it with respect to this kind of attack scenario?
Catwhisperer, there are three main challenges when defending against ransomware. First is educating the users in a meaningful way so that you aren’t playing whack-a-mole, and you have some time to dedicate to each incident. Hopefully the education component advises employees to use a different password for each online service, and to enable 2FA whenever possible. Second, the backups need to be frequent, and the solution must keep a significant number of revisions, otherwise it is fairly useless. Third, segment the network and storage/servers to limit the scope of contamination. Also, ensure that those with the highest privileges do not use the same privileges for web browsing / email as they do for system administration.
Back to this scenario – an intruder quietly penetrated the system, multiple devices, dropping problems at each point, infesting configurations, gaining access to privileged accounts, including presumably domain administration accounts. Over a minimum of 7-10 days. And all of those changes were dutifully backed up, with embedded malware. There’s a lot of simplistic nonsense that minimises the restore problem suggesting that people who suggest ‘just back up locally’ have no capacity to handle the problem. Your scenario is reasonably robust in terms of protecting the backup mechanism from being encrypted. Your appliance is on the network, so it can be detected, but as an appliance it might be hard to crack.
The problem you are left with is, how quickly did you identify and stop the threat. If it took 10 days you ca step back 10 days, but how do you roll forward, what can you safely restore that’s more current.
Secondly, how do you handle compromised privileged accounts and can you take them back before they are used to burn your site to the ground, and stop new ones being created. That ideally involves an environment based on dynamic secrets management, but that needs to be set up before, not after, an incident recovery.
You do need to ensure that the keys for your recovery service are not available in the same online environment, or they are exposed to the same risk, and open to misuse.
“the way our backup system was architected”
What’s needed is best practices for backups that are immune to these (and other) kinds of attacks. Unfortunately there probably isn’t any magic bullet, and no solution at all that doesn’t require system users to become more sophisticated.
One solution I can think of is to specifically require users to commit documents to a repository, such as git. Then back up only the (remote) repository, rather than hoovering up everything on the filesystem, including malware.
Of course, this requires users to be a little more sophisticated. But it’s high time they were, frankly.