


Facebook and its sister properties Instagram and WhatsApp are suffering from ongoing, global outages. We don’t yet know why this happened, but the how is clear: Earlier this morning, something inside Facebook caused the company to revoke key digital records that tell computers and other Internet-enabled devices how to find these destinations online.
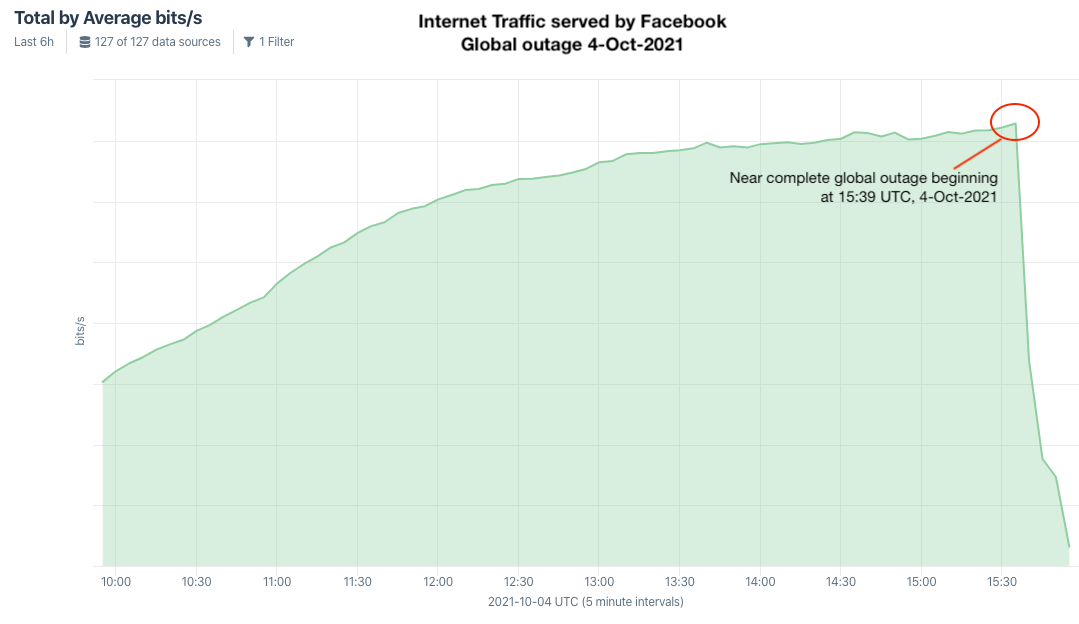
Kentik’s view of the Facebook, Instagram and WhatsApp outage.
Doug Madory is director of internet analysis at Kentik, a San Francisco-based network monitoring company. Madory said at approximately 11:39 a.m. ET today (15:39 UTC), someone at Facebook caused an update to be made to the company’s Border Gateway Protocol (BGP) records. BGP is a mechanism by which Internet service providers of the world share information about which providers are responsible for routing Internet traffic to which specific groups of Internet addresses.
In simpler terms, sometime this morning Facebook took away the map telling the world’s computers how to find its various online properties. As a result, when one types Facebook.com into a web browser, the browser has no idea where to find Facebook.com, and so returns an error page.
In addition to stranding billions of users, the Facebook outage also has stranded its employees from communicating with one another using their internal Facebook tools. That’s because Facebook’s email and tools are all managed in house and via the same domains that are now stranded.
“Not only are Facebook’s services and apps down for the public, its internal tools and communications platforms, including Workplace, are out as well,” New York Times tech reporter Ryan Mac tweeted. “No one can do any work. Several people I’ve talked to said this is the equivalent of a ‘snow day’ at the company.”
The outages come just hours after CBS’s 60 Minutes aired a much-anticipated interview with Frances Haugen, the Facebook whistleblower who recently leaked a number of internal Facebook investigations showing the company knew its products were causing mass harm, and that it prioritized profits over taking bolder steps to curtail abuse on its platform — including disinformation and hate speech.
We don’t know how or why the outages persist at Facebook and its other properties, but the changes had to have come from inside the company, as Facebook manages those records internally. Whether the changes were made maliciously or by accident is anyone’s guess at this point.
Madory said it could be that someone at Facebook just screwed up.
“In the past year or so, we’ve seen a lot of these big outages where they had some sort of update to their global network configuration that went awry,” Madory said. “We obviously can’t rule out someone hacking them, but they also could have done this to themselves.”
Update, 4:37 p.m. ET: Sheera Frenkel with The New York Times tweeted that Facebook employees told her they were having trouble accessing Facebook buildings because their employee badges no longer worked. That could be one reason this outage has persisted so long: Facebook engineers may be having trouble physically accessing the computer servers needed to upload new BGP records to the global Internet.
Update, 6:16 p.m. ET: A trusted source who spoke with a person on the recovery effort at Facebook was told the outage was caused by a routine BGP update gone wrong. The source explained that the errant update blocked Facebook employees — the majority of whom are working remotely — from reverting the changes. Meanwhile, those with physical access to Facebook’s buildings couldn’t access Facebook’s internal tools because those were all tied to the company’s stranded domains.
Update, 7:46 p.m. ET: Facebook says its domains are slowly coming back online for most users. In a tweet, the company thanked users for their patience, but it still hasn’t offered any explanation for the outage.
Update, 8:05 p.m. ET: This fascinating thread on Hacker News delves into some of the not-so-obvious side effects of today’s outages: Many organizations saw network disruptions and slowness thanks to billions of devices constantly asking for the current coordinates of Facebook.com, Instagram.com and WhatsApp.com. Bill Woodcock, executive director of the Packet Clearing House, said his organization saw a 40 percent increase globally in wayward DNS traffic throughout the outage.
Update, 8:32 p.m. ET: Cloudflare has published a detailed and somewhat technical writeup on the BGP changes that caused today’s outage. Still no word from Facebook on what happened.
Update, 11:32 p.m. ET: Facebook published a blog post saying the outage was the result of a faulty configuration change:
“Our engineering teams have learned that configuration changes on the backbone routers that coordinate network traffic between our data centers caused issues that interrupted this communication,” Facebook’s Santosh Janardhan wrote. “This disruption to network traffic had a cascading effect on the way our data centers communicate, bringing our services to a halt.”
“We want to make clear at this time we believe the root cause of this outage was a faulty configuration change,” Janardhan continued. “We also have no evidence that user data was compromised as a result of this downtime.”
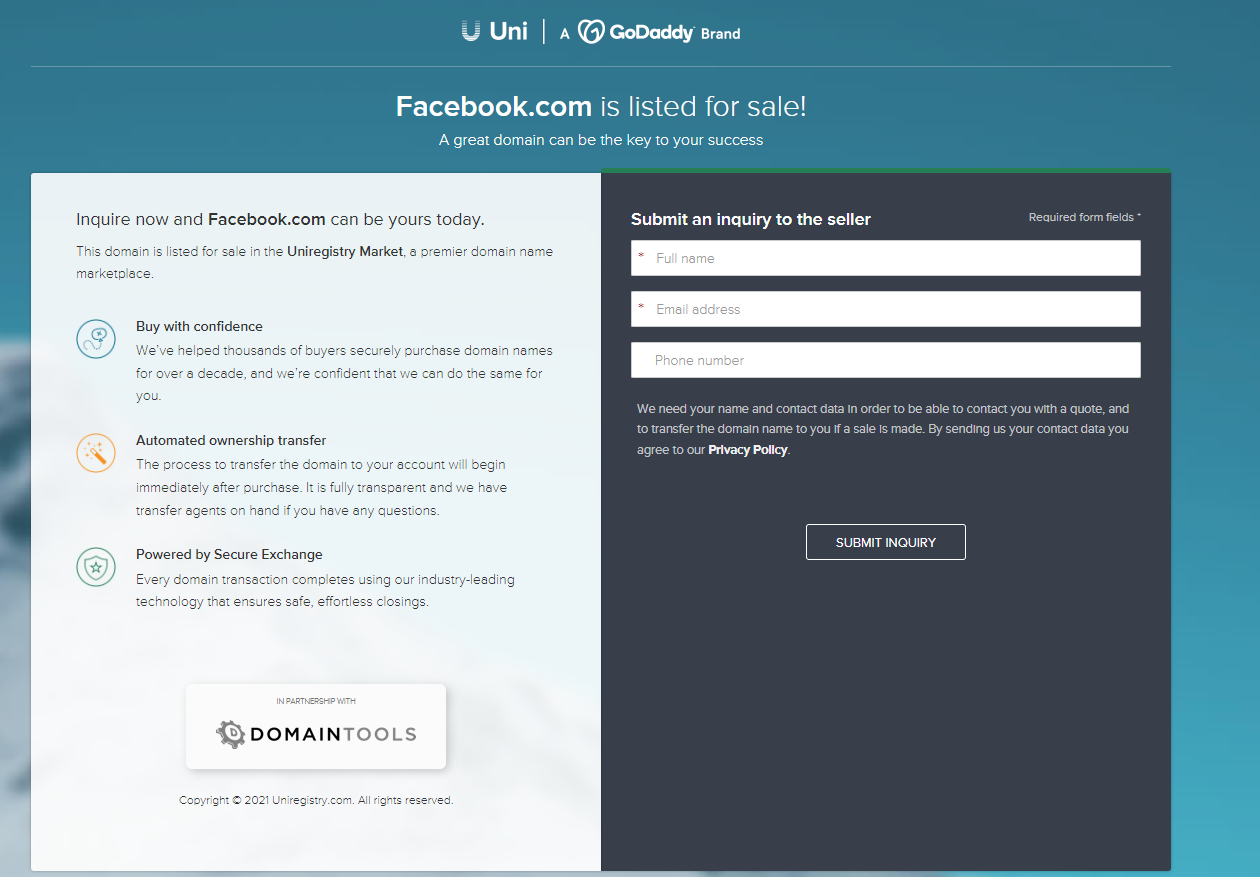
Several different domain registration companies today listed the domain Facebook.com as up for sale. This happened thanks to automated systems that look for registered domains which appear to be expired, abandoned or recently vacated. There was never any reason to believe Facebook.com would actually be sold as a result, but it’s fun to consider how many billions of dollars it could fetch on the open market.
This is a developing story and will likely be updated throughout the day.

Hmmmmm… I love speculation!
1) Honest Mistake
2) Something bad was happening and they pulled the plug to stop the bleeding.
Clearly there was more than just missing routes which caused this. Hopefully they will share a detailed account of what happened. Hopefully it was not a security incident.
Why is it “clearly” to you?
Routes are the circulatory system of all IT.
A small mistake in BGP can do a lot of damage, and it looks just like this.
Hmmmmm… I love speculation!
1) Honest Mistake
2) Something bad was happening and they pulled the plug to stop the bleeding.
I think it’s deliberate. Childish response to being outed. “Better do as we say, or else no play.
Of course if I were a company with a paid website, I would be PISSED.
Good riddance.
+10
I think this comment is shortsighted. Why one might not care about Facebook specifically, the underlying weaknesses this exposes is fascinating to any technologist. I’m in awe that something as simple as BGP routes can take down a company that arguably has infinite money to prevent outages. It should be a wake-up call for all of us in tech.
It’s always been that way?
Agree with Jack Hannigan. Obviously only one way in is a problem for engineers who are ‘outside’. And yet emergency ways in (to at least some things) is obviously ALSO a problem because you are creating security backdoor(s). A team needs to think through how to design multiple paths with multiple checks on use that is simple enough to work and to avoid unintended hack points. I miss the days when the access was by the lock to the machine room, and the systems guy had both the mainframe and the entire network in another box inside those same four walls.
“has infinite money to prevent outages”
One of the biggest mistakes that executives make… is that money can solve problems. Even infinite money can’t produce absolute results.
Now how will my information be sold?
Whenever I hear about BGP I am reminded of this little ditty: https://youtu.be/RT-1DU33xIk
(my apologies if this gets posted 3x; site is generating errors)
They had to pull the plug…
-Senator asks Facebook CEO to answer questions on teen safety… Sorry I never got the message…
-they got everyone’s info for sale on the dark web!!! Pull the plug!!!!!! The security guard had to do it cause the engineers were locked out of the buildings…
Zuckerberg ordered the crash !.
To stop the millions of potentially BAD comments about the declarations made by the whistle-blower, last night.
“Independent fact checkers, confirm that rat chewed the power cord of the server”
I believe it is a violation and an infringement upon our constitutional rights!!!!
This could be the beginning of the end of social media.
We live in hope that our lives will turn back to pre antisocial media.
Wishful thinking — a welcome diversion, though.
Fact check that.
why not living without FB and all of Zuckerberg ?
think about it, and get back your freedom !
Bombed back into the stone age! I luv it!
I hope its not a 768K BGP issue?
denique
It looks like a political thing to me. I can imagine millions of people hit the streets to restore facebook
I think some people will blame Russians,
When it comes back online you mean, no doubt.
The world is a better place without it.
I was hoping they were under attack by a data-shredding horde of unstoppable trojans.
I am showing this to be related to a Ffmpeg.dll library issue. But don’t see that showing up anywhere.
Good riddance!
The world is a much much better place without it. We werent ready as a civilization for this. Not enough safeguards in place.
Maybe try again in 50 years.
“Unfettered free-market solution”
Proof of all proof great clouds are as weak as their weakest link
Clouds are scaleable problems before they become scaleable solutions.
How obvious! The easiest way to pull their entire network down while Zuckerburg shreds all the evidence. Wake up people!!
Exactly, Zuckerberg needed to shred the evidence of the crimes that Facebook perpetrates on minors as well as hiding its intentional censorship if conservative speech and its internal corruption including assisting in the take over of the American government by stealing the election.
I don’t like to think that way, but it’s happened before, and will happen again,,, so could be.
… and isn’t it nice to know that a day could go by without Facebook, and no one died!? May we have a few more, please?
That’s easy! Just don’t use FB and tada! You got more days without it. As many days as you want, in fact.
Having trouble with this site, too. Especially when trying to post. Maybe this one with go through
Sorry for the slowness. This site had one of its busiest traffic days ever (if not THE busiest) today. We were serving >14,000 requests per minute at one point in the day. So I’m just happy that it stayed up for the most part 🙂
I was getting a lot of 502 Server Errors. Glad it was because the site was so busy. And glad to see it all worked out.
Exactly, Zuckerberg needed to shred the evidence of the crimes that Facebook perpetrates on minors as well as hiding its intentional censorship if conservative speech and its internal corruption including assisting in the take over of the American government by stealing the election.
Bizarre ,,pourtant j’y suis arrivé d’entré par le cache
facebook is up people.. why are you still here?
All sites are working fine now.
Shows what a house of cards the Internet is!
Agree with Jack Hannigan. Obviously only one way in is a problem for engineers who are ‘outside’. And yet emergency ways in (to at least some things) is obviously ALSO a problem because you are creating security backdoor(s). A team needs to think through how to design multiple paths with multiple checks on use that is simple enough to work and to avoid unintended hack points. I miss the days when the access was by the lock to the machine room, and the systems guy had both the mainframe and the entire network in another box inside those same four walls.
Yeah, DR exercises are supposed to be well planned and rehearsed for this very reason.
Most likely, there was emergency access, but some engineers may not know about it, then word gets out to the media that they can’t get in. But they do get in eventually.