


Facebook and its sister properties Instagram and WhatsApp are suffering from ongoing, global outages. We don’t yet know why this happened, but the how is clear: Earlier this morning, something inside Facebook caused the company to revoke key digital records that tell computers and other Internet-enabled devices how to find these destinations online.
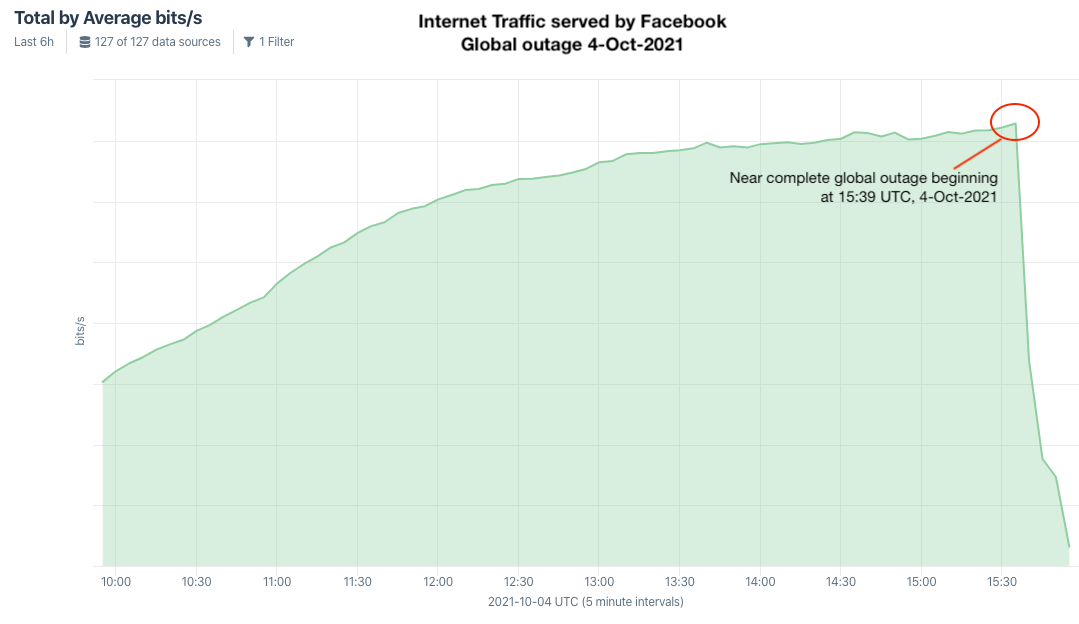
Kentik’s view of the Facebook, Instagram and WhatsApp outage.
Doug Madory is director of internet analysis at Kentik, a San Francisco-based network monitoring company. Madory said at approximately 11:39 a.m. ET today (15:39 UTC), someone at Facebook caused an update to be made to the company’s Border Gateway Protocol (BGP) records. BGP is a mechanism by which Internet service providers of the world share information about which providers are responsible for routing Internet traffic to which specific groups of Internet addresses.
In simpler terms, sometime this morning Facebook took away the map telling the world’s computers how to find its various online properties. As a result, when one types Facebook.com into a web browser, the browser has no idea where to find Facebook.com, and so returns an error page.
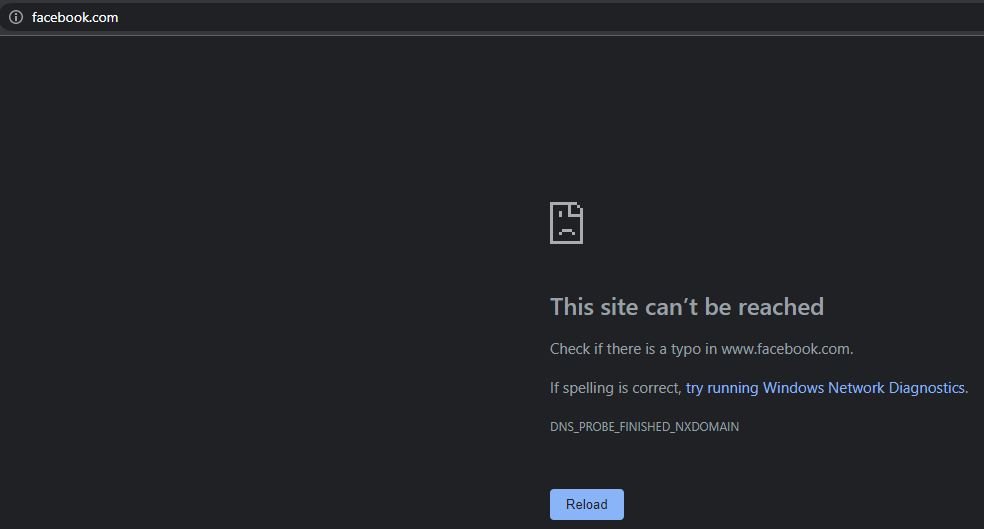
In addition to stranding billions of users, the Facebook outage also has stranded its employees from communicating with one another using their internal Facebook tools. That’s because Facebook’s email and tools are all managed in house and via the same domains that are now stranded.
“Not only are Facebook’s services and apps down for the public, its internal tools and communications platforms, including Workplace, are out as well,” New York Times tech reporter Ryan Mac tweeted. “No one can do any work. Several people I’ve talked to said this is the equivalent of a ‘snow day’ at the company.”
The outages come just hours after CBS’s 60 Minutes aired a much-anticipated interview with Frances Haugen, the Facebook whistleblower who recently leaked a number of internal Facebook investigations showing the company knew its products were causing mass harm, and that it prioritized profits over taking bolder steps to curtail abuse on its platform — including disinformation and hate speech.
We don’t know how or why the outages persist at Facebook and its other properties, but the changes had to have come from inside the company, as Facebook manages those records internally. Whether the changes were made maliciously or by accident is anyone’s guess at this point.
Madory said it could be that someone at Facebook just screwed up.
“In the past year or so, we’ve seen a lot of these big outages where they had some sort of update to their global network configuration that went awry,” Madory said. “We obviously can’t rule out someone hacking them, but they also could have done this to themselves.”
Update, 4:37 p.m. ET: Sheera Frenkel with The New York Times tweeted that Facebook employees told her they were having trouble accessing Facebook buildings because their employee badges no longer worked. That could be one reason this outage has persisted so long: Facebook engineers may be having trouble physically accessing the computer servers needed to upload new BGP records to the global Internet.
Update, 6:16 p.m. ET: A trusted source who spoke with a person on the recovery effort at Facebook was told the outage was caused by a routine BGP update gone wrong. The source explained that the errant update blocked Facebook employees — the majority of whom are working remotely — from reverting the changes. Meanwhile, those with physical access to Facebook’s buildings couldn’t access Facebook’s internal tools because those were all tied to the company’s stranded domains.
Update, 7:46 p.m. ET: Facebook says its domains are slowly coming back online for most users. In a tweet, the company thanked users for their patience, but it still hasn’t offered any explanation for the outage.
Update, 8:05 p.m. ET: This fascinating thread on Hacker News delves into some of the not-so-obvious side effects of today’s outages: Many organizations saw network disruptions and slowness thanks to billions of devices constantly asking for the current coordinates of Facebook.com, Instagram.com and WhatsApp.com. Bill Woodcock, executive director of the Packet Clearing House, said his organization saw a 40 percent increase globally in wayward DNS traffic throughout the outage.
Update, 8:32 p.m. ET: Cloudflare has published a detailed and somewhat technical writeup on the BGP changes that caused today’s outage. Still no word from Facebook on what happened.
Update, 11:32 p.m. ET: Facebook published a blog post saying the outage was the result of a faulty configuration change:
“Our engineering teams have learned that configuration changes on the backbone routers that coordinate network traffic between our data centers caused issues that interrupted this communication,” Facebook’s Santosh Janardhan wrote. “This disruption to network traffic had a cascading effect on the way our data centers communicate, bringing our services to a halt.”
“We want to make clear at this time we believe the root cause of this outage was a faulty configuration change,” Janardhan continued. “We also have no evidence that user data was compromised as a result of this downtime.”
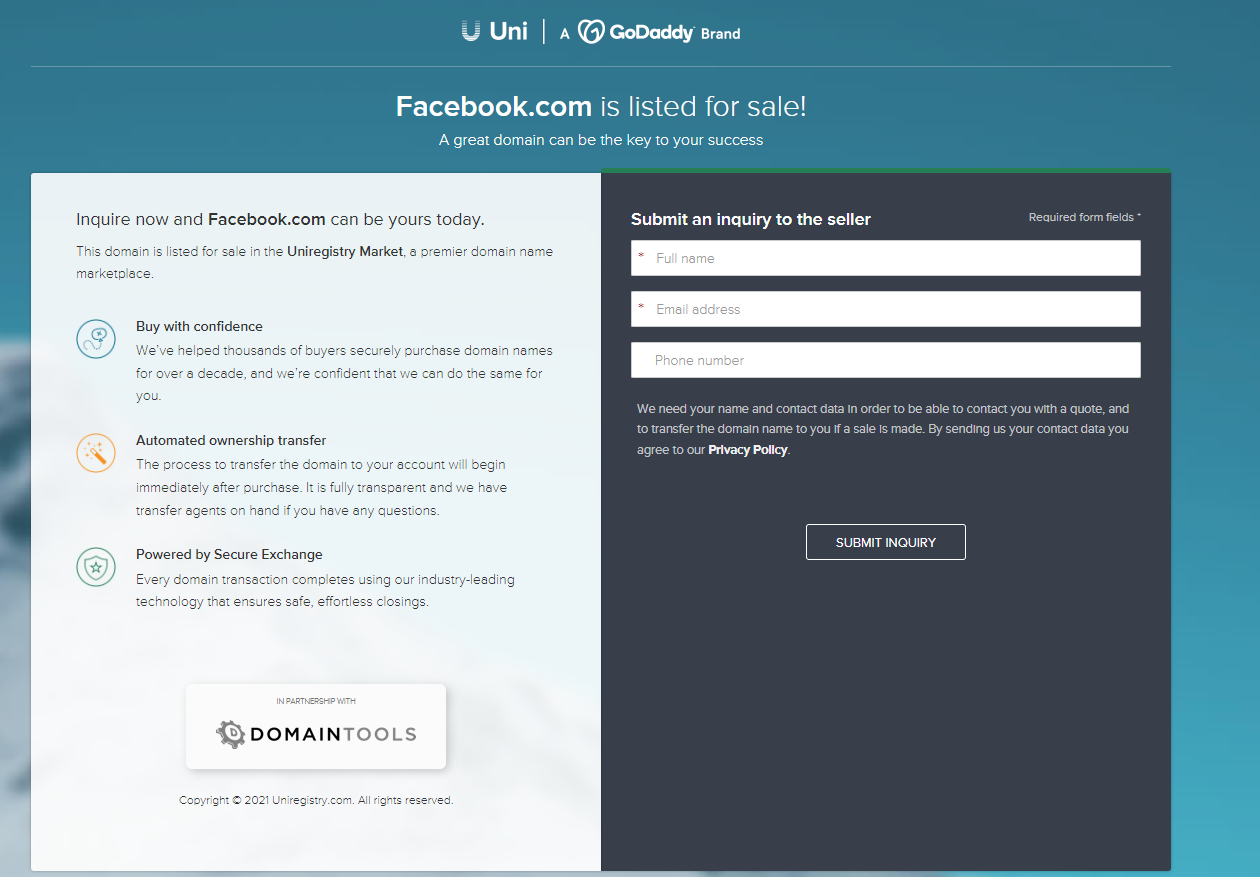
Several different domain registration companies today listed the domain Facebook.com as up for sale. This happened thanks to automated systems that look for registered domains which appear to be expired, abandoned or recently vacated. There was never any reason to believe Facebook.com would actually be sold as a result, but it’s fun to consider how many billions of dollars it could fetch on the open market.
This is a developing story and will likely be updated throughout the day.

Hey Brian, slight typo: “There’s was never any reason to believe Facebook.com would actually be sold” Thanks for the read!
Where did all my friends go? When Facebook came back I lost all my Facebook contents. I have no friends no past posts no nothing. It’s like I just downloaded it.
To the pub? And: Friends are there to share your troubles – so just meet them and weep on their shoulders.
interesting to see that twitter is the only one who puts their NameServers in different Subnets/Domains/ASNR …
-> https://twitter.com/stoege/status/1445278018344296455/photo/1
Why we cant access facebook by the ip address? The post only stand that the bgp route related with authoritative dns server were unavailable, but i suspect the hole public network of facebook were unavailable because we camt access facebook by the ip address.
The underlying cause was that FB essentially removed all their BGP (Border Gateway Protocol) routes. No packets could reach FB’s servers because there were no announced routes to the servers.
In the first minutes, this looked like a DNS problem because the DNS servers were gone, but was really a routing problem.
true, the IP is still valid associated to the name, but the route from host to host lays in the dark. The telephone book is valid, but the line is cut.
…And the door locks all suddenly _failed_ because the phone line got cut,
so nobody could even get in to fix it! 😀 Ted Kaczynski gets a good chuckle.
Facebook strangulated my business yesterday and caused me a very huge lost….
your website is your castle not facebook.
As a good business owner, you should not rely solely on someone else’s business.
I.E. single point of failure, redundancy, or whatever you what to say.
What a joke! 1 hour after CBS interview! #deletefacebook facecrook lies on everything, a user = someone who comes ONCE a month! Su<kerberg wants to control everything, but when there is a problem "i was not informed"…
Facebook Hear
With FB, IG, and WA holding onto Billions of peoples data I’m outraged This company didn’t plan for the worst. How can we trust them with AI and machine learning?
The answer – you can’t!
But if you haven’t decided they’re untrustworthy yet strictly on the basis of them allowing the public to suffer for their own bottom line, then well….
Thanks for sharing such a detailed analysis.
> No one can do any work.
No one? Wow. 100% of my staffed worked just fine. We don’t rely on very poorly secured, external, sites in order to function. Do you?
Although the “breakdown” was repaired relatively quickly, I would still like to summarize some results.
It is known that Facebook shares fell in one day – by more than 5% (which is hundreds of millions of dollars). However, this is not important for ordinary users of the social network.
First, the shutdown of all Facebook systems, which lasted about six hours, not only deprived three billion users of the company access to Facebook and its services: Instagram and WhatsApp; but also affected the internal systems of employees.
Second, the shutdown was so severe that not only ordinary workers but also engineers (who were tasked with helping solve the problem) could not log in at first.
Involuntarily forced to agree with D. Medori, director of the company monitoring the network “Kentik” (which actually analyzes the state of the “World Wide Web” or the Internet). In an interview with CNN, he said that for many people, Facebook is “the Internet,” and that he “does not know if he has seen such a shutdown before in a large Internet company.”
The fact that a company of such size and resources as Facebook has been offline for more than four hours suggests that there is no quick fix.
R. Shaban (Google and Wiki analyst)
https://en.edupro.expert/facebook-crisis-find-best-result
Something I don’t understand… An Autonomous System such as Facebook (ASN 32934) should have a “unified internal routing policy.” Removal of the BGP prefixes should have affected traffic TO Facebook, as is surely did. But why was routing WITHIN Facebook disrupted?
In old-school networking, we had literally dozens of routing protocols to choose from, and as we had a wealth of layer-1 and layer-2 protocols to choose from. So the chances that an organization would be running the same IGP (internal gateway protocol) and EGP (external gateway protocol) were essentially nil; one chose best-of-breed for each independently, and they have very different needs.
By about 1996, the EGP choice had devolved into a monoculture of people running BGP, and that makes sense, because convergence on a single protocol is driven by the Network Effect, just as a common trading language makes it possible to do business across borders… Knowing that you’d be using the same routing protocol with all your external neighbors decreased the time and effort needed to reach the goal. Unfortunately, when we reached an EGP monoculture, competitive pressure also went away. We were using BGPv4 in 1996, and we’re still using the same version now today, twenty-five years later, with literally no significant improvement or development to the protocol. And although it played no part in yesterday’s incident, the thin layer of security that’s added on to the side of BGPv4 to try to remedy its worst deficiencies has actually _lost_ significant ground since its peak in about 2003-2004.
It took longer for IGPs to die out, and when they did, the monoculture that took hold was in the form of “iBGP,” which meant simply using BGP for internal routing as well as external routing, even though it was a technically much worse choice for the purpose… and I’m afraid I was one of the people who pushed that forward, in the name of efficiency and, frankly, laziness. A lot of the poor Internet engineering choices that we’re now living with the consequences of were done in the name of laziness, in times when businesses were striving for exponential growth, money was plentiful, but time and attention were scarce and growing scarcer. So today, essentially _every_ network of global scale runs BGP as both their external and internal routing protocol
And it’s in this environment that a problem like the one Facebook had becomes possible. Pushed to simultaneously grow and cut costs, their engineering departments are hollowed out, losing the entire middle to a bipolar structure of a very small handful of the same old farts that I was working with when they were kids, thirty years ago, who actually know how things work, and a lot of actual kids who are paid a pittance and given no meaningful path to intellectual and career growth; where before they’d have had mentors and a ladder of ever-more-challenging work to make their way up, now their growth path is blocked by automation. “Dev Ops” automation that allows the attention of a team of two or three or four people to be spread across thousands of routers and tens or hundreds of thousands of servers through abstracted fleet management, using the kids for “rack & stack” grunt-work, where they never get to touch anything that they could break, but also never get to learn how it works. Like I said, I’m dealing with exactly the same small set of people now, in my counterpart networks, that I was thirty years ago… but some of them are starting to retire, others are wanting more time with family, and we’re all just getting old; this isn’t sustainable. So, in this environment of too little attention from too few senior people stretched too thin, and using too many abstraction layers of automation that was all-too-often written for unrelated purposes, you get own-goals like yesterday’s, where the senior people have to dig through layers and layers of crufty scripts in half a dozen languages (an area where there has _not_ been useful consolidation) to find and remediate the problem, while the junior folks are _literally_ locked out and unable to help.
It’s worthy of note that this monoculture/stagnation process has certainly not been limited to routing protocols; where we had many competing and improving layer-2 protocols, since about 2001 they’ve pretty much all been squeezed out by Ethernet in its many, equally mediocre, forms. There used to be dozens of email formats, with a rich market in gateways between; since that competition was eliminated, email has become homogenous and an efficient home for spammers. It’s precisely this trend toward stagnation in open standards and open protocols that has made the predatory centralization of proprietary garbage like Gmail and Office365 and Facebook possible… When there were alternatives, nobody would ever have given such half-assed things a second glance.
Very nice, thank you.
You’re a national treasure, Bill. What an awesome reply. <3
To paraphrase Winston Churchill, “[X] is the worst of all forms of [whatever], except for all the others.” It is quite a shame how so many of the competing products in every field of networking and IT have withered and died. There were features in Word Perfect that I quite like, and features in the current Microsoft Office that I quite hate. They eliminated Clippy with forcing me to do things a certain way, and it drives me nuts. I started in IT in the early ’80s and it’s now such a homogeneous mess these days.
How true that is. I also started in the early 80s, in the days of linear access. While the technological improvements can’t be denied, the solutions to problems have certainly become a homogenous horror show.
so, as an untutored layman who knows little about the nuts and bolts of IT, why is that, if I may ask, sir ?
Claimed expertise is starting IT in the 80’s and liking wordperfect, possibly clippy.
“Homogenous mess” the next claim. Why do things wither and die, in IT/www/x86?
Why indeed? All existential questions cannot be answered by all who exist.
To decode further, send $5 cash and a self-addressed stamped envelope to:
LegacyWebRants, wholly owned subsidiary of Compuserve
IT (HR) Department, c/o Larry Johnson (he’ll know)
(*Include 25+ years of evidence you’ve beaten your head against technological walls unnecessarily)
Thanks for informative post.
As an old timer, wouldn’t you require your engineers to have an open back door connection to your router when making any major changes?
This wasn’t one router, it was effectively all of them.
And most of those connections are TCP/IP which wasn’t routable once the command was executed.
Thank you for your insight. Sounds like you have been around for a while, so let me ask you; if knowledge loss through the aging out of architects and developers, a lack of standards and the other issues you touch on is a problem (and it is) how do we fix this?
I saw this up close when I took on contracting work as a business analyst and technical writer. For instance when the DOJ mandated that BellSouth facilitate local competition we had to touch just about every system they had. Most of these systems were built on mainframes, written in COBOL etc. 30 or more years ago and we now had whiz kids on Windows PCs who had never heard of COBOL attempting to build a front end for ordering and provisioning phone lines, either being a process that may touch a dozen or more legacy systems. The braintrust who created those systems left behind little if any documentation. Their ordering system worked, so it was left alone to do it’s thing for decades. Now we had to figure out what every program did and how they interacted and so forth…while they were working and without breaking anything. It took four years work by hundreds of us. Because we had to feel our way through.
So, basically the same things you point out in your reply.
We know the problems, we need solutions. As someone who has ‘been there, done that’ do you have any thoughts on this (aside from ‘document everything’ which we’ve learned folks just aren’t going to do and current knowledge management systems suck even if they do)?
Thanks!
The people who wrote those old COBOL programs had the same thought as the people who write the current Java programs: “my code documents itself!” and “if you want to know what it does, just read the code!”. It has always been a losing fight to get programmers to document their code. Mangers don’t push it because there is no profit in documentation.
I have found that in many cases the real question isn’t, “What does this code do?”, but rather, “Why is this code doing this?” The :what” part should be described in the story associated with the code and the “why” part is handled with appropriate constant, function, object, variable names, and comments.
For example:
for (int i = 3; i <= 10; i++)
{
y(x(i));
}
wouldn't pass my code review.
private const int FIRSTHEADERROW = 3
private const int LASTHEADERROW = 10
for (int currentHeaderRow = FIRSTHEADERROW; currentHeaderRow <= LASTHEADERROW; currentHeaderRow++)
{
ValidateHeaderRow(rows(currentHeaderRow));
}
would pass my code review.
And yes, I'm ignoring things like comments explaining why the constant values are defined as they are and storing the constants in a config file or a database, in order to provide a simplified example.
Honesty.. wow kudos to you Mr. Woodcock.. lol.. now if only other ivory tower sys admins and cio’s could choose honesty over cya to save their jobs.
“I’m afraid I was one of the people who pushed that forward, in the name of efficiency and, frankly, laziness. A lot of the poor Internet engineering choices that we’re now living with the consequences of were done in the name of laziness, in times when businesses were striving for exponential growth, money was plentiful, but time and attention were scarce and growing scarcer.”
unfortunately.. unwillingness to skill upgrade younger workers either out of fear of being replaced or being overburdened by their work load due to greed and incompetence by upper management or just apathy.. this is affecting all of america.
many thanks and great respect for; Mr. Bill Woodcock, and several others on this thread. In response to ‘ You cant handle the truth’ – I also think it is affecting America, which is of great concern to me since I am an American, I have kids, and I wonder about the future. There seem to be some remarks directed toward character, as opposed to strictly technical or logistical factors. References to laziness, greed, honesty, etc.- sound like at least some of the seven deadly sins are represented here.
Is the fault with how the network was set up or with human nature being what it it ? From comments here, there seems to be some limit to the machine as built. Or with us. Which one is it ?
Planned Obsolescence
Legacy Compatibility
Limited Liability
sorida, eco fatto..
Thank you for a very informative and thorough explanation!
I appreciate your analysis of the issue, but what are the possible solutions to address the problem? Does it become necessary to completely rebuild the whole system, or are there less drastic answers which affect only certain specific areas of concern? Your description of the current system sounds just short of collapse, with very few people having the knowledge and ability to ensure it keeps working. Without a proactive group trying to spread the knowledge of how everything works, we will approach a systemic failure. Or at least that appears to be where it’s going.
Thank you for the excellent write up, I enjoyed the read. The only down side to your write up is it kills the conspiracy theory it was all due to Decaf Coffee being ordered by mistake. 🙂 Thank you again! Excellent write up!
Decaf could still have been involved! Which reminds me of one of my favorite Dilberts. Wally my hero!
https://dilbert.com/strip/2003-06-19
‘reload in 5’
Twitter is not the only one, that’s a common best-practice.
James 1 … Let’s bring in the Lord!
As someone who works in Operations, I find it hard to believe that someone in FB would make that type of change in the middle of the workday. Call me a skeptic…
https://twitter.com/briankrebs/status/1445184339524956161
The proposed short UT didn’t work as planned 🙂
And as someone who doesn’t work in Operations but knows some stuff, I find it hard to believe that someone at FB could make such a fundamental change without it being checked once, twice, three times before implementation. (Because I’m sure it’s all down to something stupid like, “Oops, we put a comma at the end of line 15 of the new config file when it should have been a semi-colon at the end of the line.” type of thing.) But why worry, it’s not as if when you mess up your BGP router configuration anything bad will happen, right? 😛
Chief guru taking charge. They don’t _make_ mistakes. _Then_ they do.
FB banned me years ago after I was there a couple of weeks. I don’t have an iron in the fire – I don’t care about FB. But maybe FB got pissed at all the criticism and pulled the plug for a few hours to see how they liked it. That is how I think, that is what I’d do if I was in charge. But I’m not $$ / greed motivated. Being the social media crowd is $$ motivated, it probably was not revenge motivated.
But when you listen to all the dems suffering from perfection dis-ease, they believe FB is such a terrible place and want it perfectly censored to meet their narrow minded world view.
WTf are you on about?
Or, someone fat-fingered a legit change
TLDR: believes striving for “perfection” is a “dis-ease” and basically tacitly defends hate speech, medical disinformation, covert foreign-backed conspiracy theory BS to undermine the gullible contrarian nutters in the uneducated and anti-science Republican sack of same. Deliberate misinformation is not a virtue – unless you’re truly a traitor trying to get people killed and undermine societies, for that purpose, while pretending to be a good actor unconvincingly even according to your own internal data and employees. You defend all that, you deserve a hard look.
It seems too convenient for this to be a mistake. They have a news story that makes them look horrible and it gets buried by a bigger news story of them being down.
Hanlon’s Razor:
Never attribute to malice that which is adequately explained by stupidity.
Oh malice has pushed many a genius to stupidity. You better believe it!
Never assume malicious intent when incompetence is an option.
I’ve thought about that too. Very costly, but they did get to play the victim’ish and hopping the noise from it is louder than the noise from their political manipulation.
Either way – it will work to their advantage in this situation, mistake or not.
I don’t see that as a winning strategy.
They appear incompetent and evil at the same time. It does not appear to give them any advantage. And I doubt any evil mastermind would even think that would work.
They still get the reputational loss from the whistleblower saying that Facebook had the research that their platform was being used for political disinformation, and they chose to ignore (not censor) it, but rather let the algorithm promote it. The 6 hour outage didn’t distract from that, as it will be a long term discussion over the next few years.
It will be a continuing discussion but that will not occur among the average facebook user.
The average user is only looking at headlines in the media. The headlines of them being evil was dominated by the news of them being down.
It is a very common strategy to distract with bigger news.
It’s common to distract with an announcement of news to try and change the narrative.
It is NOT common, nor is it a smart strategy, to burn down an entire building just to distract from a dumpster fire.
The average user wasn’t going to dump Facebook or boycott their services based on the whistleblower basically confirming what people already believed to be true.
Yet, even a 6 hour outage costs Facebook millions in ad revenue, billions in stock damage, and far more reputational damage as people are more hesitant to rely on Facebook, WhatsApp, Instagram now that it is apparent that a major outage can occur.
If you did want to believe in a conspiracy to distract… it would be the other way around.
A whistleblower allegation would be the story as an attempt to distract the news cycle from a major outage.
We’ve now reached a point where tightly linked systems, fragmentation of IT training, lack of computer knowledge by decision makers, and increasing payoffs for cyber crime and cyber warfare have created the “perfect storm” of conditions for increasingly frequent and massive failures of information systems. This will severely impact the management, analysis and communication of critical information that’s essential for dealing with climate change.
I have worked in the hosting networking space for decades. I am amazed that FB would have all their DNS (and uplink) eggs in one basket.
There should be enough resiliency built in that the loss of a single routing domain will result in a sub-optimal performance, not a complete outage. In other words, a failure like this should send users to the next-best location (EMEA, or Asia, etc). The experience wont be as good, but it wont be an outage. In the meantime, their engineers can figure out what happened and fix it – instead of reading about themselves in the media and updating their resumes….
It sounds like Facebook had a slight separation between DNS and everything else. But they also had a health check: when DNS servers couldn’t reach a system, they’d stop advertising it. This became a chicken-egg problem, because authorizing internally appears to have relied on that DNS. But with the routes all gone, the DNS was also gone and thus authorization was unavailable.
Get ready for the big media blackout when the election fraud results from every state come out. Also the info about social media, fake news, big pharma, Drs, nurses, CDC, WHO all blocked info on Hydroxycloriquine and Ivermectin curing everything…within hours that would’ve prevented all of the WuFlu restrictions and losses of freedoms we have now. Crimes against humanity are getting close for them allnand they have to block it from the sheep.
LOL get some help, dude.
The only sheep I see are the Qanon conspiracy theorists still trolling the internet like you.
“all blocked info on Hydroxycloriquine and Ivermectin curing everything”
Apparently not stupidity?
Great snark, SteveBot.
Frank the Christmas Gargoyle admitted it was him, playing with spells and not knowing what he was doing. That sounded reasonable to me.
I have a few friends that are now reporting that someone has created fake Instagram acct in their name. Me thinks the Facebook outage was more than an outage..
Happens every day, every hour. Even a legit outage, means scammers are still going to be doing what they do.
Unrelated social media shenanigans are unrelated.
Did my script blocker block this?
I have seen more than Packet Clearing House say ~40%. Then Cloudflare says 3,000% increase in DNS queries with some degradation of performance.
Perhaps this is a function of Cloudflare architectural choices where the goal is certainty of resolution even during extreme DDoS events? So that they are exchanging better resilience in the face of targeted hostile traffic over resilience to failures? This is a significant difference and understanding the cause of it could be valuable. Or maybe Cloudflare is just marketing its awesomeness and calculated using statistical models that showed the greatest increase. This would be the most simple and obvious explanation, reporting numbers that include only FB DNS requests as the baseline.
I saw that Facebook denied, very specifically, using an angle grinder to get into the server cages but has made no mentions of the many rumors of needing a drill to get through a no-physical-failback-public-Internet-using digital lock. I have also seen some CS alumni snarking on the centrality of data science to FB tech interviews, so that protocol knowledge is undervalued. Perhaps knowledge of BGP & DNS might now be prioritized rather than the generic technical interview questions for those hired as network engineers.
Here is the highly enjoyable animation of Facebook deleting itself from the Internet.
https://twitter.com/sweis/status/1445164016184090628
Welp. A 6 hour outage doesn’t look so bad anymore when the entirety of Twitch was dumped today.
Excellent observation Marcus.
Whoever did this said it was an accident and Facebook wanted to believe it
If someone with the access wanted to do this, their options are to explain what they did and face repercussions, maybe even prison, or say it was an accident, get reassigned and be a folk hero
Possibly a clever way to demonstrate how important you are to the World, or should I say “Critical”. Maybe this incident merits tagging Facebook as Critical Infrastructure. Have fun with that, Facebook!
Thanks for the explanation.
What a peaceful couple of hours ….I hoped the nightmare was finally over for good, the coincidence with the whistleblower on 60 minutes was just too curious to be true:-)….but its all back up and running.
I have no farcebook or finstergram account and wouldn’t mind if they vanish…
Rod
Cisco offers a service calls Crosswork Network Insights that monitors changes in BGP routing advertisements. Had Facebook been using this service, they likely could have identified and mitigated the problem a lot faster. Give our white paper a read to understand what likely happened at Facebook.
https://www.cisco.com/c/en/us/products/cloud-systems-management/crosswork-network-automation/the-risks-of-traffic-hijacking.html#~how-bgp-works