With little more than a month to go before the start of the 2016 tax filing season, the IRS and the states are hunkering down for an expected slugfest with identity thieves who make a living requesting fraudulent tax refunds on behalf of victims. Here’s what you need to know going into January to protect you and your family.
 The good news is that the states and Uncle Sam have got a whole new bag of technological tricks up their sleeves this coming tax season. The bad news is ID thieves are already testing those defenses, and will be working against a financially strapped federal agency that’s been forced to cede much of its ability to investigate and prosecute such crimes.
The good news is that the states and Uncle Sam have got a whole new bag of technological tricks up their sleeves this coming tax season. The bad news is ID thieves are already testing those defenses, and will be working against a financially strapped federal agency that’s been forced to cede much of its ability to investigate and prosecute such crimes.
Tax refund fraud affects hundreds of thousands, if not millions, of U.S. citizens annually. Victims usually first learn of the crime after having their returns rejected because scammers beat them to it. Even those who are not required to file a return can be victims of refund fraud, as can those who are not actually due a refund from the IRS.
By all accounts, the IRS has improved at blocking phony refund requests. The agency estimates it prevented $24.2 billion in fraudulent identity theft refunds in 2013. Trouble is, it paid out some $5.8 billion in fraudulent refunds that year that it later determined were bogus, and experts say that is only the fraud the agency knows about, and the true number is likely much higher annually.
Perhaps in response to the IRS’s increasing ability to separate phony returns from legitimate ones, crooks last year massively focused on filing bogus refund requests with the 50 U.S states. To head off a recurrence of that trend in the 2016 filing season, the states and the IRS have hammered out an agreement to examine more than 20 new data elements collected by online providers like TurboTax and H&R Block.
Those new data elements include checking for the repetitive use of the same Internet address to rapidly file multiple returns, and reviewing computer device information (browser user agent string, cookies e.g.) tied to the return’s origin. Another check involves measuring the time it takes to file a return; fraudsters involved in tax refund fraud tend to breeze through returns in just a few minutes because they are generally copying and pasting information into the tax forms, or relying on an automated program to do it for them.
The hope is that the these new checks will let investigators more accurately flag suspicious refund requests processed by tax preparation firms, which also have agreed to beef up lax security around customer accounts. Under the agreement, online providers will enforce:
- new password standards to include a minimum of eight characters, with upper, lowercase, alphanumerical and special characters;
- a lock-out feature that blocks users with too many unsuccessful login attempts;
- the addition of three security questions;
- some sort of out-of-band verification for email addresses — sending an email or text to the customer with a personal identification number (PIN).
Julie Magee, Alabama’s chief tax administrator, said the state/IRS task force opted not to disclose all 20 of the data elements they will be collecting from tax prep firms.
“The thieves are going to figure these out on their own, and they’re already testing our defenses,” Magee told KrebsOnSecurity. “We don’t want to do anything to make that easier for them.”
ANALYSIS
Whether or not we see an increase in tax refund fraud next year, one thing seems certain: the IRS will prosecute far fewer of the crooks involved. Congress has persistently underfunded the IRS, and budget cuts have pushed prosecutions of identity thieves to a new low. According to the IRS’s 2015 Annual Report, IRS identity theft criminal investigations are down almost 50 percent since 2013.
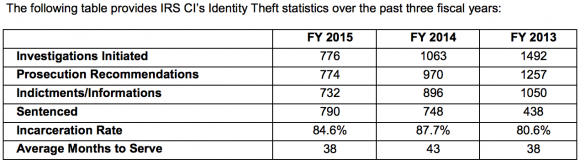
Tax fraudsters were so aggressive last year that they figured out how to steal consumer identities directly from the agency itself. In August 2015, the IRS disclosed that crooks abused the “Get Transcript” feature on its Web site to steal Social Security numbers and information from previous years’ tax filings on more than 334,000 Americans.
The IRS has responded to the problem of tax ID theft partly by offering Identity Protection PINs (IP PINs) to affected taxpayers that must be supplied on the following year’s tax application before the IRS will accept the return. However, consumers still have to request an IP PIN by applying for one at the agency’s site, or by mailing in form 14039 (PDF).
Incredibly, the process that thieves abused to steal tax transcripts from 334,000 taxpayers this year from the IRS’s site also works to fraudulently obtain a consumer’s IP PIN. In fact, the following redacted screen shot from a notorious cybercrime forum shows a seasoned tax fraudster teaching would-be scammers how to use the IRS’s site to obtain a victim’s IP PIN.
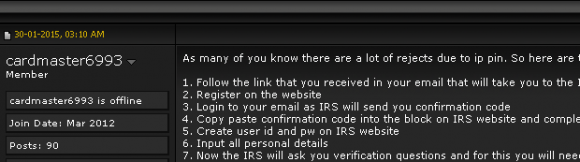
Continue reading →



 New authentication methods now offered by Yahoo! and to a beta group of Google users let customers log in just by supplying their email address, and then responding to a notification sent to their mobile device.
New authentication methods now offered by Yahoo! and to a beta group of Google users let customers log in just by supplying their email address, and then responding to a notification sent to their mobile device.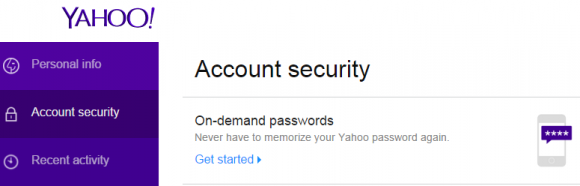

 The FTC sued Oracle over years of failing to remove older, more vulnerable versions of Java SE when consumers updated their systems to the newest Java software. Java is installed on more than 850 million computers, but only recently (in Aug. 2014) did the company change its updater software to reliably remove older versions of Java during the installation process.
The FTC sued Oracle over years of failing to remove older, more vulnerable versions of Java SE when consumers updated their systems to the newest Java software. Java is installed on more than 850 million computers, but only recently (in Aug. 2014) did the company change its updater software to reliably remove older versions of Java during the installation process. Mountain View, Calif. based Gyft lets customers buy and use gift cards entirely from their mobile devices. Acting on a tip from a trusted source in the cybercrime underground who reported that a cache of account data on Gyft customers was on offer for the right bidder, KrebsOnSecurity contacted Gyft to share intelligence and to request comment.
Mountain View, Calif. based Gyft lets customers buy and use gift cards entirely from their mobile devices. Acting on a tip from a trusted source in the cybercrime underground who reported that a cache of account data on Gyft customers was on offer for the right bidder, KrebsOnSecurity contacted Gyft to share intelligence and to request comment.

 IT helpdesk guy by day and security researcher by night, 31-year-old Chris Vickery said he unearthed the 21 gb trove of MacKeeper user data after spending a few bored moments searching for database servers that require no authentication and are open to external connections.
IT helpdesk guy by day and security researcher by night, 31-year-old Chris Vickery said he unearthed the 21 gb trove of MacKeeper user data after spending a few bored moments searching for database servers that require no authentication and are open to external connections. This type of scam mainly impacts brick-and-mortar retailers that issue gift cards when consumers return merchandise at a store without presenting a receipt. Last week I heard from KrebsOnSecurity reader Lisa who recently went online to purchase a bunch of steeply discounted gift cards issued by pet supply chain Petco.
This type of scam mainly impacts brick-and-mortar retailers that issue gift cards when consumers return merchandise at a store without presenting a receipt. Last week I heard from KrebsOnSecurity reader Lisa who recently went online to purchase a bunch of steeply discounted gift cards issued by pet supply chain Petco.

