The U.S. Department of Homeland Security (DHS) has been quietly launching stealthy cyber attacks against a range of private U.S. companies — mostly banks and energy firms. These digital intrusion attempts, commissioned in advance by the private sector targets themselves, are part of a little-known program at DHS designed to help “critical infrastructure” companies shore up their computer and network defenses against real-world adversaries. And it’s all free of charge (well, on the U.S. taxpayer’s dime).
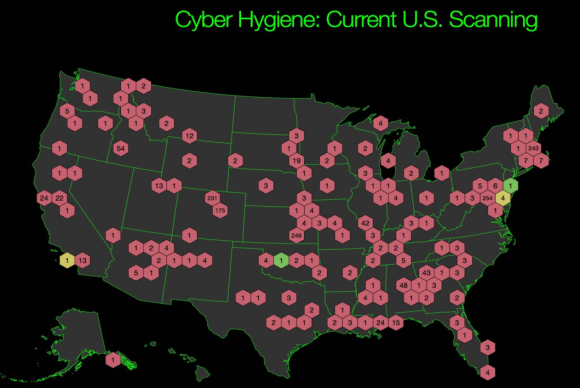
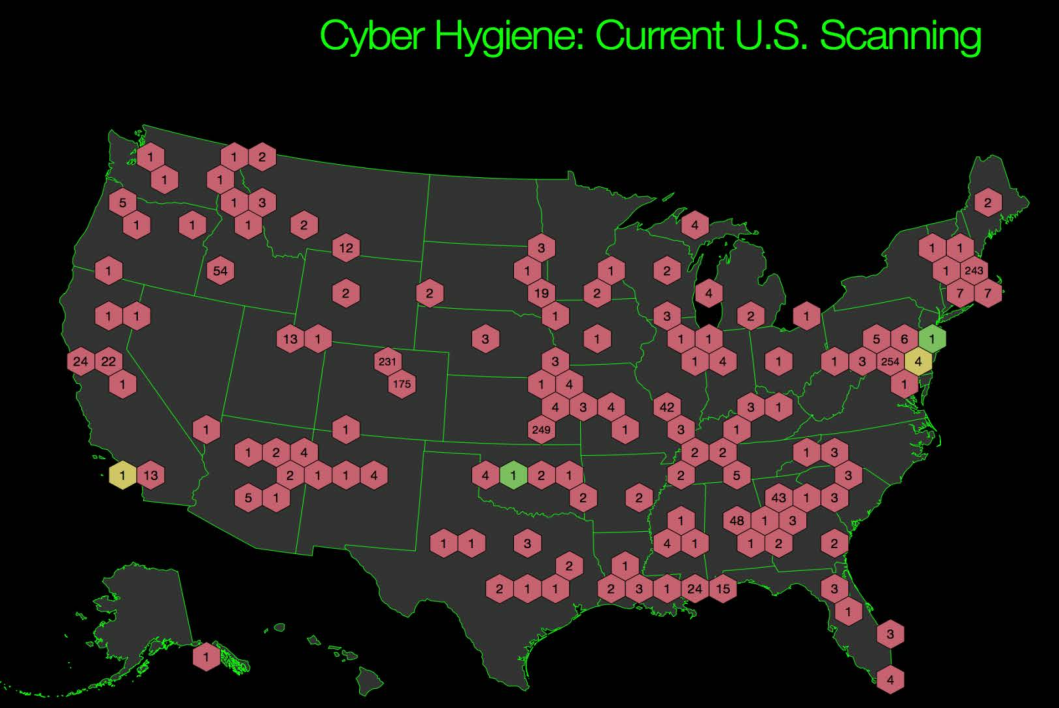
Organizations participating in DHS’s “Cyber Hygiene” vulnerability scans. Source: DHS
KrebsOnSecurity first learned about DHS’s National Cybersecurity Assessment and Technical Services (NCATS) program after hearing from a risk manager at a small financial institution in the eastern United States. The manager was comparing the free services offered by NCATS with private sector offerings and was seeking my opinion. I asked around to a number of otherwise clueful sources who had no idea this DHS program even existed.
DHS declined requests for an interview about NCATS, but the agency has published some information about the program. According to DHS, the NCATS program offers full-scope penetration testing capabilities in the form of two separate programs: a “Risk and Vulnerability Assessment,” (RVA) and a “Cyber Hygiene” evaluation. Both are designed to help the partner organization better understand how external systems and infrastructure appear to potential attackers.
“The Department of Homeland Security (DHS) works closely with public and private sector partners to strengthen the security and resilience of their systems against evolving threats in cyberspace,” DHS spokesperson Sy Lee wrote in an email response to an interview request. “The National Cybersecurity Assessments and Technical Services (NCATS) team focuses on proactively engaging with federal, state, local, tribal, territorial and private sector stakeholders to assist them in improving their cybersecurity posture, limit exposure to risks and threats, and reduce rates of exploitation. As part of this effort, the NCATS team offers cybersecurity services such as red team and penetration testing and vulnerability scanning at no cost.”
The RVA program reportedly scans the target’s operating systems, databases, and Web applications for known vulnerabilities, and then tests to see if any of the weaknesses found can be used to successfully compromise the target’s systems. In addition, RVA program participants receive scans for rogue wireless devices, and their employees are tested with “social engineering” attempts to see how employees respond to targeted phishing attacks.
The Cyber Hygiene program — which is currently mandatory for agencies in the federal civilian executive branch but optional for private sector and state, local and tribal stakeholders — includes both internal and external vulnerability and Web application scanning.
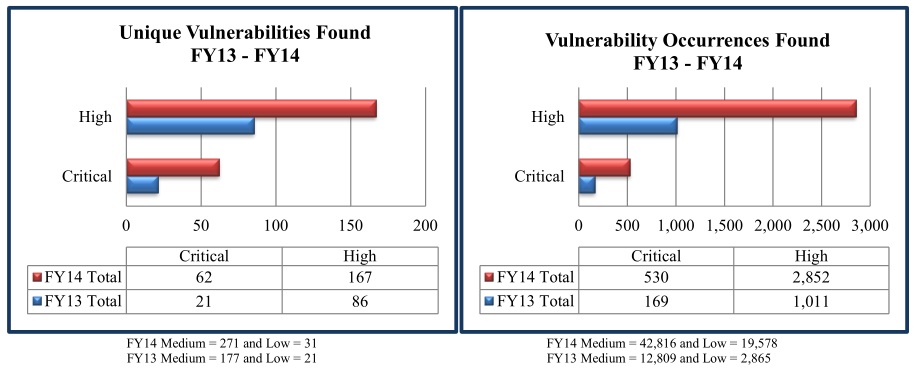
The reports show detailed information about the organization’s vulnerabilities, including suggested steps to mitigate the flaws. DHS uses the aggregate information from each client and creates a yearly non-attributable report. The FY14 End of Year report created with data from the Cyber Hygiene and RVA program is here (PDF).
Among the findings in that report, which drew information from more than 100 engagements last year:
-Manual testing was required to identify 67 percent of the RVA vulnerability findings (as opposed to off-the-shelf, automated vulnerability scans);
-More than 50 percent of the total 344 vulnerabilities found during the scans last year earned a severity rating of “high” (4o percent) or “critical” (13 percent).
-RVA phishing emails resulted in a click rate of 25 percent.
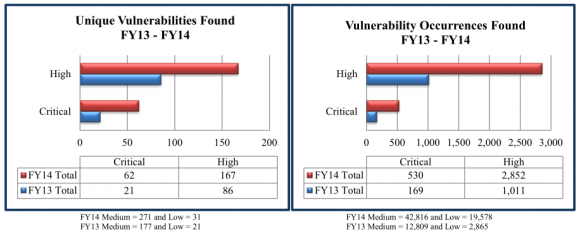
Data from NCATS FY 2014 Report.
ANALYSIS
I was curious to know how many private sector companies had taken DHS up on its rather generous offers, since these services can be quite expensive if conducted by private companies. In response to questions from this author, DHS said that in Fiscal Year 2015 NCATS provided support to 53 private sector partners. According to data provided by DHS, the majority of the program’s private sector participation come from the energy and financial services industries — with the latter typically at regional or smaller institutions such as credit unions.
DHS has taken its lumps over the years for not doing enough to gets its own cybersecurity house in order, let alone helping industry fix its problems. In light of the agency’s past cybersecurity foibles, the NCATS program on the surface would seem like a concrete step toward blunting those criticisms.
I wondered how someone in the penetration testing industry would feel about the government throwing its free services into the ring. Dave Aitel is chief technology officer at Immunity Inc., a Miami Beach, Fla. based security firm that offers many of the same services NCATS bundles in its product. Continue reading →



 Mountain View, Calif. based Gyft lets customers buy and use gift cards entirely from their mobile devices. Acting on a tip from a trusted source in the cybercrime underground who reported that a cache of account data on Gyft customers was on offer for the right bidder, KrebsOnSecurity contacted Gyft to share intelligence and to request comment.
Mountain View, Calif. based Gyft lets customers buy and use gift cards entirely from their mobile devices. Acting on a tip from a trusted source in the cybercrime underground who reported that a cache of account data on Gyft customers was on offer for the right bidder, KrebsOnSecurity contacted Gyft to share intelligence and to request comment.


 IT helpdesk guy by day and security researcher by night, 31-year-old Chris Vickery said he unearthed the 21 gb trove of MacKeeper user data after spending a few bored moments searching for database servers that require no authentication and are open to external connections.
IT helpdesk guy by day and security researcher by night, 31-year-old Chris Vickery said he unearthed the 21 gb trove of MacKeeper user data after spending a few bored moments searching for database servers that require no authentication and are open to external connections. The good news is that the states and Uncle Sam have got a whole new bag of technological tricks up their sleeves this coming tax season. The bad news is ID thieves are already testing those defenses, and will be working against a financially strapped federal agency that’s been forced to cede much of its ability to investigate and prosecute such crimes.
The good news is that the states and Uncle Sam have got a whole new bag of technological tricks up their sleeves this coming tax season. The bad news is ID thieves are already testing those defenses, and will be working against a financially strapped federal agency that’s been forced to cede much of its ability to investigate and prosecute such crimes.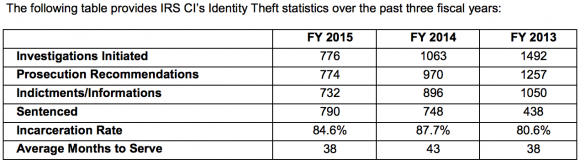
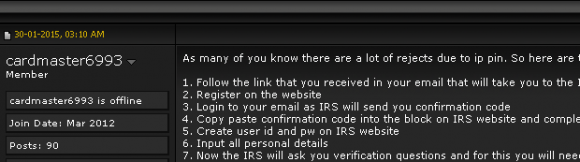
 This type of scam mainly impacts brick-and-mortar retailers that issue gift cards when consumers return merchandise at a store without presenting a receipt. Last week I heard from KrebsOnSecurity reader Lisa who recently went online to purchase a bunch of steeply discounted gift cards issued by pet supply chain Petco.
This type of scam mainly impacts brick-and-mortar retailers that issue gift cards when consumers return merchandise at a store without presenting a receipt. Last week I heard from KrebsOnSecurity reader Lisa who recently went online to purchase a bunch of steeply discounted gift cards issued by pet supply chain Petco.